相信很多人都會發現,當透過 ChatGPT 生成圖表或PDF檔案時,通常只要遇到繁體中文字,就會出現亂碼或方塊顯示錯誤,實際要解決 ChatGPT 中文亂碼錯誤,只要用一句字體修正指令就能輕鬆解決,後續要透過ChatGPT處理生成是圖片或PDF檔案就不會出現亂碼情況。
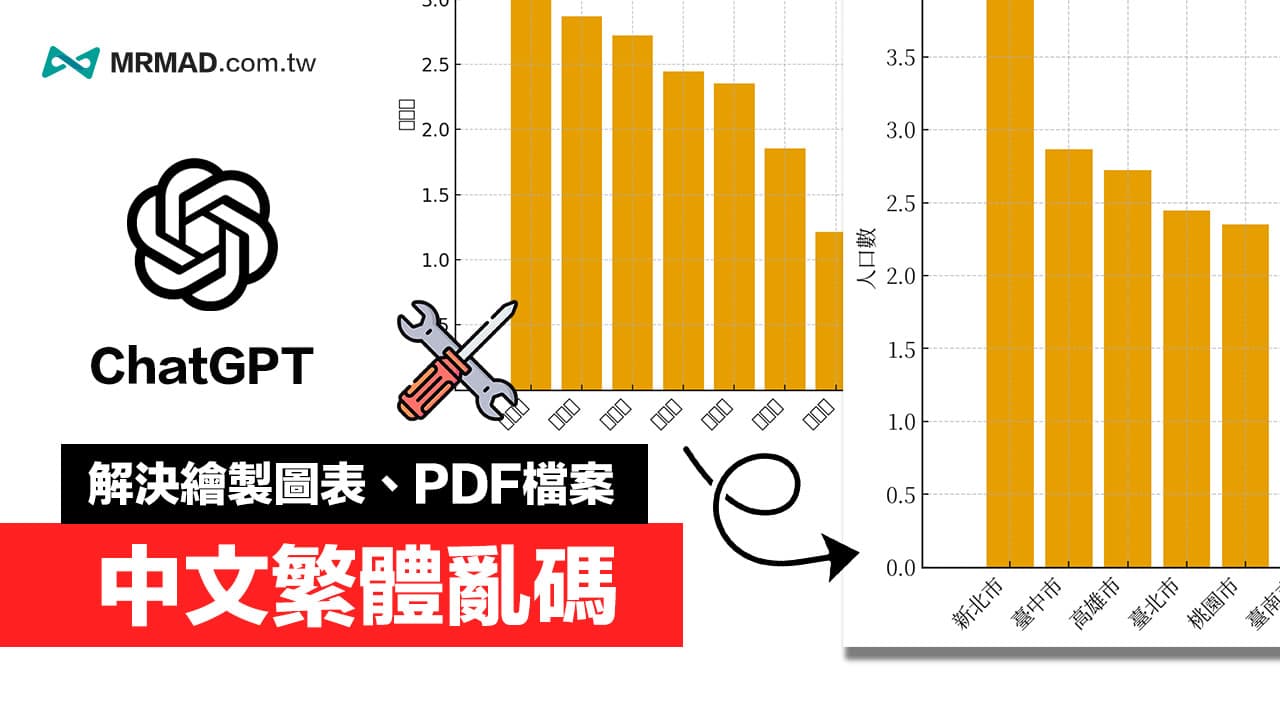
造成ChatGPT中文亂碼錯誤主要原因
實際會導致ChatGPT繪製圖表時會造成中文亂碼,最主要原因是 AI 在調用 Python 工具繪圖時,都不是會指定字體,就是隨意設定系統內不存在的字體,才會導致中文無法正確渲染,由於少了字體參數,才會造成 ChatGPT 繪製出來的圖片資料,中文字都會變成方塊亂碼無法正常顯示。
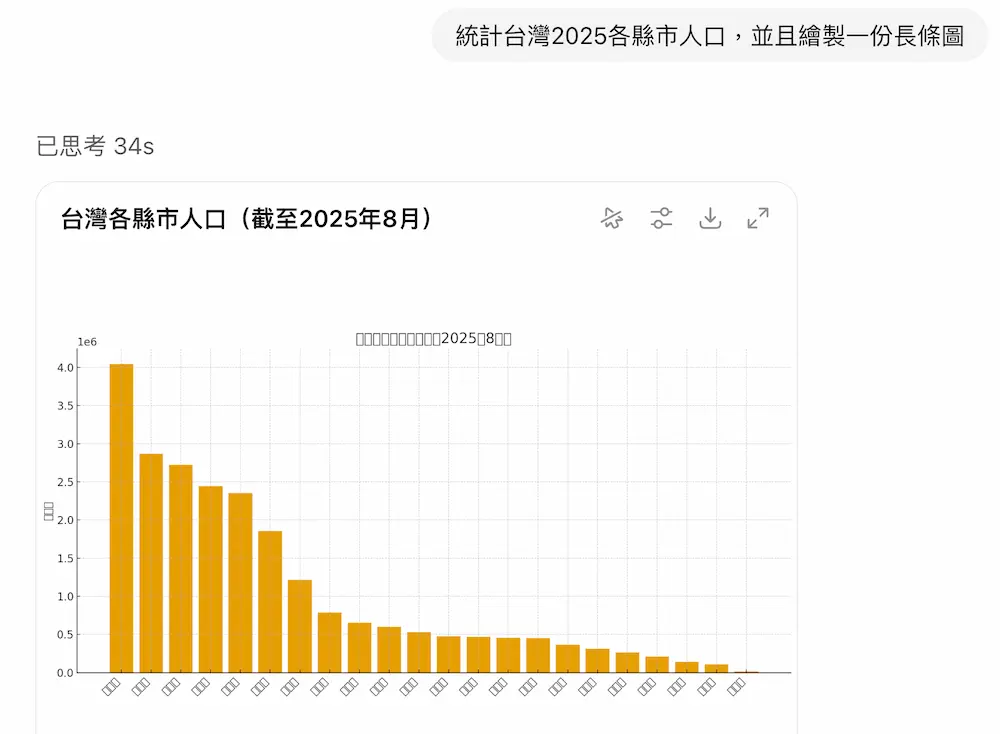
目前測試也發現,ChatGPT 內建環境中可支援中文的字體僅有少數,像是 Noto Serif CJK JP 或 Noto Sans CJK JP 才能穩定輸出中文,最終生成出來的統計圖片就能正常呈現繁體字。
至於為什麼不是用繁中版本(TC)字體才正確?主要在於目前 ChatGPT 內的 Python 執行環境僅安裝日文字體,所以想確保中文圖表能正常顯示,就必須先借用 JP 版本的字型。
如何解決ChatGPT中文繪製圖會造成亂碼?
要是想解決 ChatGPT 繪製中文圖表資料能正常顯示中文繁體字,可以多加底下套用字型 Noto Serif CJK JP 指令,讓 ChatGPT 內建 Python 工具在繪製圖表資料就能正常顯示中文字:
plt.rcParams["font.family"]="Noto Serif CJK JP
ChatGPT中文PDF檔案文字亂碼指令
要是要求ChatGPT將資料轉成PDF文件檔案,同樣也會碰見繁體中文字全是亂碼,主要是因爲當使用 ReportLab 生成 PDF 時,字體設定方式不同,才會導致亂碼情況。
要是想確保 ChatGPT 處理PDF檔案內中文字體,只要多加底下修正字體指令後,就能避免PDF檔案內資料會無法正常顯示中文問題:
pdfmetrics.registerFont(UnicodeCIDFont('HeiseiKakuGo-W5'))
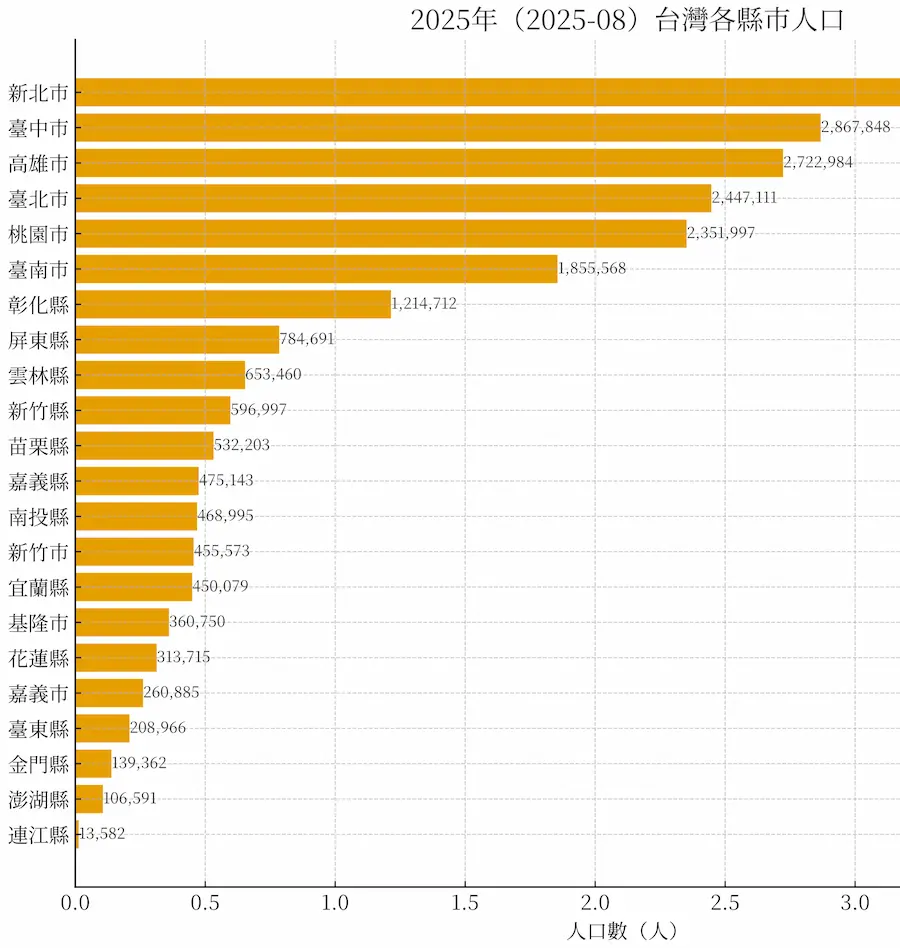
如何讓ChatGPT記憶套用中文字型方法
如果確認以上 ChatGPT 中文繪圖指令能解決亂碼問題後,也不需要每次都要多加入這些指令,只要利用 ChatGPT 記憶指令保存就可以:
【ChatGPT繪製圖表中文字支援記憶指令】
plt.rcParams["font.family"]="Noto Serif CJK JP"
【ChatGPT繪製PDF中文字支援記憶指令】
pdfmetrics.registerFont(UnicodeCIDFont('HeiseiKakuGo-W5'))
以上只要輸入過一次後,後續就不需要重複輸入指令,ChatGPT就知道在處理繪製圖片和PDF檔案時,會自動掉用正確的中文字體。
想了解更多Apple資訊、iPhone教學和3C資訊技巧,歡迎追蹤 瘋先生FB粉絲團、 訂閱瘋先生Google新聞、 Telegram、 Instagram以及 訂閱瘋先生YouTube。