Apple 近日公布最新多模態 AI 研究成果,同時推出全新統一影像模型 UniGen-1.5,不僅整合影像理解與生成功能,更進一步支援影像編輯,展現 AI 在圖像處理任務中的全方位能力。這項升級延續去年首次亮相的 UniGen 架構,強調以單一模型處理多項視覺任務,有望成為多模態大型語言模型(MLLM)領域的新基準。
Apple 研究團隊在去年發表的 UniGen 中,首次展示能同時進行影像理解與生成的統一多模態模型。此次推出的 UniGen-1.5,則進一步納入影像編輯功能,依然維持單一模型架構,跳脫過往需仰賴多個專門模型各自處理的作法。
團隊指出,整合這三項功能最大的挑戰在於任務性質差異大,尤其影像生成與編輯的技術需求並不相同。然而透過更精緻的訓練策略,UniGen-1.5 成功將這些能力融合,並展現優於多款先進模型的表現。
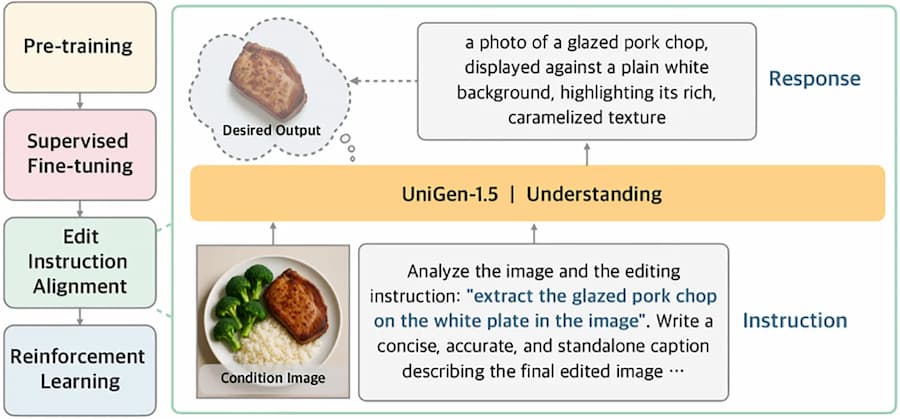
針對影像編輯難以掌握細節指令的問題,Apple 團隊新增「編輯指令對齊(Edit Instruction Alignment)」訓練階段,作為微調後的後處理步驟。這項技術讓模型學會先以文字描述方式預測目標圖片內容,進而提升後續影像生成的準確性。
團隊表示:「模型即便經過監督式微調,對於多變編輯需求仍難全面掌握,因此我們設計輕量後訓練階段,提升指令與圖像語意的對應能力。實驗證明此階段對提升編輯品質大有助益。」
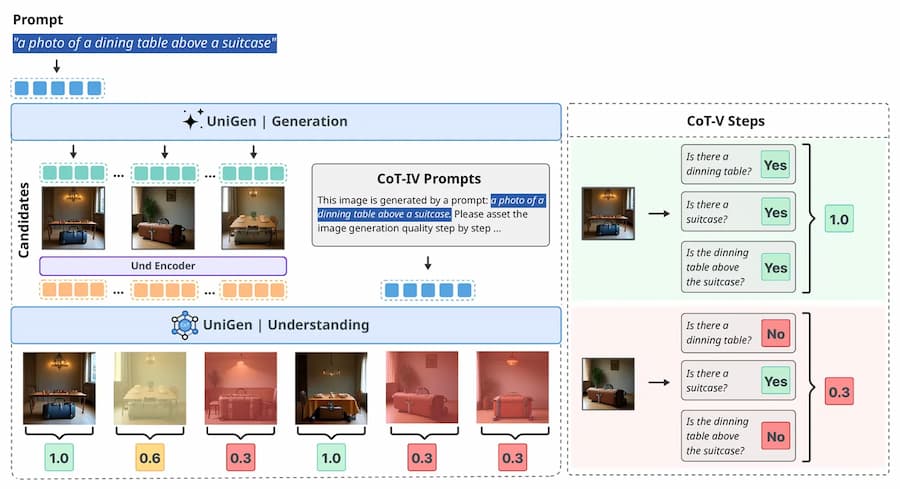
除了新增後訓練機制,UniGen-1.5 也在強化學習階段採用統一的獎勵系統,將影像生成與編輯納入同一評估標準,解決過去因變動幅度差異所導致的訓練難題。這項改進被認為是本次研究中最具代表性的技術貢獻之一。
根據多項業界標竿測試結果,UniGen-1.5 在 GenEval 和 DPG-Bench 指標上分別拿下 0.89 和 86.83 的高分,超越如 BAGEL、BLIP3o 等近期熱門模型。
影像編輯方面,在 ImgEdit 測試也取得 4.31 分,超越開源模型 OminiGen2,表現更接近商業模型 GPT-Image-1。

儘管整體表現亮眼,研究團隊也指出 UniGen-1.5 仍有改進空間,特別是在文字生成與角色一致性方面。例如模型在圖像中加入文字時,常無法精準控制字型與結構;而在處理連續影像編輯時,部分角色的面部特徵與顏色也會出現明顯變化。
Apple 研究團隊強調,後續將持續優化細節生成能力,並針對文字渲染與圖像一致性設計更細緻的訓練流程。
參考來源:Apple
想了解更多Apple資訊、iPhone教學和3C資訊技巧,歡迎追蹤 瘋先生FB粉絲團、 訂閱瘋先生Google新聞、 Telegram、 Instagram以及 訂閱瘋先生YouTube。